ソース
Oct. 6th 2025にarXivに投稿された次のpaper。
Less is More: Recursive Reasoning with Tiny Networks
Alexia Jolicoeur-Martineau
https://arxiv.org/abs/2510.04871
ソースコードが公開されていますので、試しました。
https://github.com/SamsungSAILMontreal/TinyRecursiveModels
インストール
うちの環境は、intel Z790, core i9-i14900k, rtx5090+rtx4090のローカルパソコン ubuntu gnu/linuxです。
gitコマンドでダウンロードして、venv環境をつくり、そこに入ります。
$ git clone https://github.com/SamsungSAILMontreal/TinyRecursiveModels.git
$ cd TinyRecursiveModels
$ python3 -m venv ./venv
$ source ./venv/bin/activateあとはreadmeの通り requirementsをいれます。
$ pip install -r requirements.txt # install requirements
$ pip install --no-cache-dir --no-build-isolation adam-atan2 データセットをダウンロードします。今回はテストなので一番軽いSudoku-Extremeで。
$ python dataset/build_sudoku_dataset.py --output-dir data/sudoku-extreme-1k-aug-1000 --subsample-size 1000 --num-aug 1000 # 1000 examples, 1000 augmentsトラブルシュート
次のReadmeに書かれたコマンドで学習を実行しようとしますがエラーがでます。
$ run_name="pretrain_mlp_t_sudoku"
python pretrain.py \
arch=trm \
data_paths="[data/sudoku-extreme-1k-aug-1000]" \
evaluators="[]" \
epochs=50000 eval_interval=5000 \
lr=1e-4 puzzle_emb_lr=1e-4 weight_decay=1.0 puzzle_emb_weight_decay=1.0 \
arch.mlp_t=True arch.pos_encodings=none \
arch.L_layers=2 \
arch.H_cycles=3 arch.L_cycles=6 \
+run_name=${run_name} ema=TrueModuleNotFoundError: No module named 'adam_atan2_backend'HRMのほうのissuesに解決法がありました。
https://github.com/sapientinc/HRM/issues/25
代わりにadam-atan2-pytorchを使うようです。
$ pip install adam-atan2-pytorch
$ sed -i 's/adam_atan2/adam_atan2_pytorch/g' pretrain.py
$ sed -i 's/AdamATan2/AdamAtan2/g' pretrain.py
$ sed -i 's/lr=0,/lr=0.0001,/g' pretrain.pysedでpretain.pyのadam_atan2を書き換えます。学習率の初期値は0のままだと別のエラーがでました。ので学習率の初期値も適宜設定します。
これでもう一度学習を実行すると走ります。
(もし、fatal error: Python.h: No such file or directoryという別のエラーが出た場合は、sudo apt install python3-devをしてPython.hを入れてください。)
なお、wandbを使っていませんが毎回どうするか聞かれます。
wandb: (1) Create a W&B account
wandb: (2) Use an existing W&B account
wandb: (3) Don't visualize my results
wandb: Enter your choice: 3次のようにoffline指定しておくと静かになります。
$ export WANDB_MODE=offline実行時間
L40S GPU 1つでRuntime: < 36 hoursだそうです。
うちだとRTX5090 1つで、6時間くらいかかる予想です(が、evalデータ数が多く実際には10時間ほどかかりました)。また、arch.mlp_t=Trueのとき global_batch=768でVMEM~32GB使います。

先程の実行コード(pretrain.pyに渡したパラメータ)では50000 epochの学習で5000 epochごとにevalが入ります。
VRAMは 32 GBギリギリまで使っていて、負荷もフル575Wです。gpuは効率よく利用できているようです。
mlp blockに置換しない、attention blockほうだとVRAMは21 GB使用して、4h30min程度で走りそうです(こちらもevalに時間がかかり実際には8時間10分かかりました)。

21 GBだとRTX4090でもそのまま走ります(mlp置換はout of memoryになった)。こちらもやってみると、2.76it/sで6h30minかかるということです。RTX5090のほうが44%速いです。
RTX5090+RTX4090両方を使うと、5.25 it/sでした。RTX5090の速度からすると2枚使う割に1.3倍にしかなっておらず遅い気がしますが、RTX4090で律速すると考えると5.25/2.76 = 1.9なので、ほぼ4090 2枚分の速度ということで悪くはないです。RTX4090が遅いということで…(1~2年前までは爆速のイメージでしたが)。
wandb: Run history:
wandb: num_params ▁
wandb: train/accuracy ▁▁▁▆▆▆▇▇▇▇▇█▇█▇▇▇██▇████████▇█████▇█████
wandb: train/count ▁▁▁▁████████████████████████████████████
wandb: train/exact_accuracy ▁▁▁▁▁▄▂▂▄▅▅▅▅▅▅▅▅▅▅▆█▆█▇▇▇█▇█▇▆▇▇▇▇█████
wandb: train/lm_loss █▄▂▂▂▂▂▂▂▂▂▁▂▂▂▁▂▁▁▁▁▂▁▁▁▁▁▁▁▁▂▁▁▁▁▁▁▁▁▁
wandb: train/lr ▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁
wandb: train/q_halt_accuracy ▁▁█████████████████████▇████████████████
wandb: train/q_halt_loss ▃▁▁▁▃▇▂▂█▂▂▂▁▂▁▂▁▁▂▅▂▆▁▆▄▁▃▁▂▄▁▂▂▁▂▂▂▃▂▅
wandb: train/steps ▁██▇▇▆▇▆▇▆▇▇▆▆▆▆▆▅▆▆▅▅▆▅▅▅▄▄▅▆▅▅▄▅▅▅▅█▅▅
wandb:
wandb: Run summary:
wandb: num_params 6828034
wandb: train/accuracy 0.85783
wandb: train/count 1
wandb: train/exact_accuracy 0.55914
wandb: train/lm_loss 0.66863
wandb: train/lr 0.0001
wandb: train/q_halt_accuracy 0.98925
wandb: train/q_halt_loss 0.01033
wandb: train/steps 8.6129
65100/65104 [8:10:37<00:01, 2.21it/s]後日w&bを使って結果をプロットしました。mlp版で85.2%で論文の87.4%にはなりませんでした。
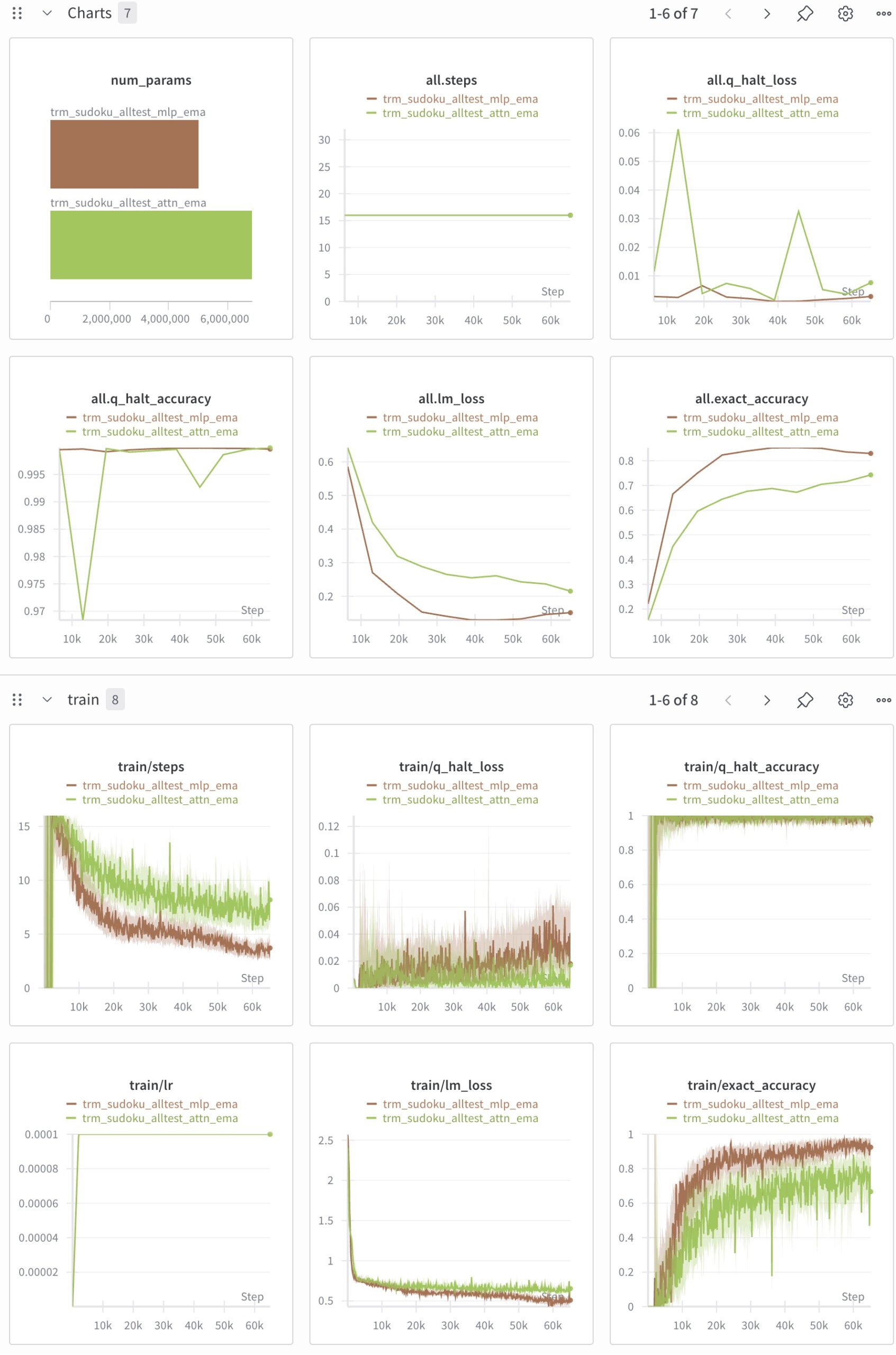
50000 epochでMLP版は過学習の傾向にあり、Attn版はもう少し長く学習できそうな感じがします。
もっと短い時間で試したいとき (transformer ベースライン)
TRMのベースラインとしてただのTransformerモデルがレポジトリに用意されていますので、それを使って5~6分で学習が終わるコードを実行します。まずは、これで挙動を確認するとよいでしょう。TRMの特徴を入れるなどして、パフォーマンスがどう変わるか見ていくとわかりやすいでしょう(epoch数を50000へ上げないと効果がでない特徴もあります。じっくり試す場合はeval数を削減するのがよいです。)。
transformers_baseline アーキテクチャは transformers_baseline.yaml / transformers_baseline.py で定義されています。
次のように実行するとRTX5090で5分20秒でした。
$ run_name="baseline_tiny_sudoku"
$ python pretrain.py \
arch=transformers_baseline \
data_paths="[data/sudoku-extreme-1k-aug-1000]" \
evaluators="[]" \
epochs=10000 eval_interval=2000 \
lr=1e-4 puzzle_emb_lr=1e-4 \
weight_decay=1.0 puzzle_emb_weight_decay=1.0 \
arch.H_layers=4 \
arch.hidden_size=256 arch.num_heads=8 \
arch.halt_max_steps=8 \
+run_name=${run_name} ema=True
この設定のポイントは次のとおりです。
arch=transformers_baseline- HRM/TRM 系ではなく、単純な transformer を使うアブレーション・モデル
Model_ACTV2を選択します。
- HRM/TRM 系ではなく、単純な transformer を使うアブレーション・モデル
arch.H_layers=4- デフォルトは 8 層ですが、4 層に減らして学習を軽くします。
arch.hidden_size=256 arch.num_heads=8- デフォルトは hidden_size=512, num_heads=12 ですが、半分程度の幅のモデルにして計算・メモリを削減しています。
- 256 ÷ 8 = 32 で、head_dim(hidden_size/num_heads)が整数になり、実装と整合します。
arch.halt_max_steps=8- ACT(Adaptive Computation Time) の外側ループで、最大何ステップ回すかを制御します。デフォルト 16 を 8 に減らして 1 イテレーション当たりの計算を半分にしています。
epochs=10000- 論文本番設定は Sudoku-Extreme で 60000 epoch 程度学習していますが、まずは 10000 にして完走時間をかなり短くしています(精度は落ちますが、「動くかどうか」を見るには十分です)。
- それ以外の
lr/weight_decay/puzzle_emb_*/emaなどは、TRM/HRM と同様のスケールをそのまま踏襲しています。
この設定で GPU メモリ使用量・学習時間はかなり軽くなるはずです。性能を上げたくなったら、H_layers を 6〜8、hidden_size を 384〜512 に戻す、epochs を増やす、といった方向でスケールさせればよいです。
学習用コードpretrain.pyのパラメータの説明
実行パラメータは、config/cfg_pretrain.yamlにかかれているものがデフォルト値です(パラメータ管理にはhydraが使われています)。
実行時に、$ pretrain.py global_batch_size=32 epochs=1 eval_interval=1などとすると、パラメータを上書きできます。
$ run_name="pretrain_xxx_sudoku"
$ python pretrain.py \
arch=trm \
data_paths="[data/sudoku-extreme-1k-aug-1000]" \
evaluators="[]" \
epochs=50000 eval_interval=5000 \
lr=1e-4 puzzle_emb_lr=1e-4 weight_decay=1.0 puzzle_emb_weight_decay=1.0 \
... \
+run_name=${run_name} ema=True
run_name="pretrain_xxx_sudoku"- シェル変数。後半の
+run_name=${run_name}で Hydra/PretrainConfig のrun_nameフィールドに流し込み、ログディレクトリ名や Weights & Biases のラン名に使われます。
- シェル変数。後半の
python pretrain.py- すべてのトレーニングを実行するエントリポイント。中で Hydra を使って設定を構築し、DataLoader・モデル・オプティマイザなどを立ち上げています。
arch=trm- Hydra の config group
archでtrm.yamlを選択し、アーキテクチャ名recursive_reasoning.trm@TinyRecursiveReasoningModel_ACTV1を指定します。
- Hydra の config group
data_paths="[data/sudoku-extreme-1k-aug-1000]"- 学習に使う Puzzle データセット(ここでは Sudoku-Extreme)のディレクトリを指定。
- 事前に
build_sudoku_dataset.pyで生成したディレクトリを想定しています。
evaluators="[]"- 学習中に走らせる Evaluator(ARC 評価など)を空にする指定。Sudoku-Extreme のみで、単にトレーニングロスなどを見る用途。
epochs=50000- 全データセットを何周するか(エポック数)。Sudoku-Extreme 実験は論文では 60000 epoch 程度が使われていますが、ここでは 50000 に少し短縮した例になっています。
eval_interval=5000- 何エポックごとに評価フェーズ(
evaluatorsがあればそれも含む)を実行するか。
- 何エポックごとに評価フェーズ(
lr=1e-4- モデル本体(TRM)の学習率。論文でも全タスクで 1e-4 を使用。
puzzle_emb_lr=1e-4- 「パズル埋め込み」用の別学習率。ARC では puzzle embedding に大きめの LR(1e-2) を使っていますが、Sudoku では 1e-4 に合わせています。
weight_decay=1.0- モデル本体に対する AdamW の weight decay。Sudoku/Maze では 1.0 を使用(かなり強めの正則化)。
puzzle_emb_weight_decay=1.0- puzzle embedding パラメータに対する weight decay。
+run_name=${run_name}- Hydra の「追加」オプション(先に設定されている run_name を上書きせず、ここで新たにセットするイメージ)。
PretrainConfig.run_nameに値を入れます。
- Hydra の「追加」オプション(先に設定されている run_name を上書きせず、ここで新たにセットするイメージ)。
ema=True- Exponential Moving Average(EMA) を有効化。
cfg_pretrain.yamlではema_rate: 0.999がデフォルトで設定されており、TRM は Sudoku/Maze で EMA を使うことで overfitting の暴走を防いでいます。
- Exponential Moving Average(EMA) を有効化。
TRM の arch.* パラメータの意味
使用するモデルは archで渡します。arch=trmだとTRMを使い、arch=hrmだとHRMを使います。モデルの構造はconfig/arch/trm.yamlに書かれています。
trm.yaml と TinyRecursiveReasoningModel_ACTV1Config に対応する項目です。
(a) arch.L_layers=2
L_layers: 低レベル推論ネットワーク(L レベル)の層数(Transformer/MLP ブロック数)。- 論文では Sudoku-Extreme に対して「2層」が最も良いテスト性能を示したと報告されています。
(b) arch.H_cycles=3 arch.L_cycles=6
H_cycles- 外側の再帰回数 T に対応。TRM では「解 y を改善する大きなステップ」を何回繰り返すかを決めます。
L_cycles- 各 H ステップの中で L レベルのネットワークを何回回すか(n に対応)。
- 実装側では、
H_cycles-1回は勾配無しで再帰し、最後の 1 回だけ勾配付きで再帰する構造になっています(メモリ節約・効果的な深い再帰)。 - Sudoku-Extreme に対しては
T = 3, n = 6(つまりH_cycles=3, L_cycles=6)が最も汎化性能が良かったと論文中の Table 3 で示されています。
(c) arch.mlp_t=True(MLP 版だけ)
mlp_t:- True のとき、L レベルの token-mixing を self-attention ではなく「シーケンス長方向に MLP をかける」 MLP-Mixer 風の層に差し替えます。
- Sudoku のように「グリッドが小さく固定(9×9)」なタスクでは、self-attention よりもこの MLP 版の方が一般化が良くなると論文で報告されています(Sudoku-Extreme の精度が 74.7% → 87.4%)。
(d) arch.pos_encodings=none(MLP 版だけ)
pos_encodings- 位置エンコーディングの種類。TRM/HRM では通常 rotary positional encoding(rope) を使いますが、ここでは
noneにして「位置埋め込み無し」にしています。 - MLP-Mixer 版では、固定サイズの 9×9 グリッドを仮定しており、位置情報を明示的に使わなくても十分な性能が出る、という設計になっています。
- 位置エンコーディングの種類。TRM/HRM では通常 rotary positional encoding(rope) を使いますが、ここでは
(e) self-attention 版 (pretrain_att_sudoku) の違い
run_name="pretrain_att_sudoku"
...
arch.L_layers=2 \
arch.H_cycles=3 arch.L_cycles=6 \
+run_name=${run_name} ema=True
arch.mlp_tやarch.pos_encodingsを上書きしていないので、trm.yamlのデフォルトに従います:mlp_t: False→ L レベルで通常の self-attention を使用。pos_encodings: rope→ Rotary positional encoding を使用。
- 再帰回数 (H_cycles/L_cycles) や層数 (L_layers) は MLP 版と同じなので、「アーキテクチャだけ変えた TRM-Att vs TRM-MLP」という比較になります。
ARC-AGI-1を試す
データセットを作成します。
# ARC-AGI-1
python -m dataset.build_arc_dataset \
--input-file-prefix kaggle/combined/arc-agi \
--output-dir data/arc1concept-aug-1000 \
--subsets training evaluation concept \
--test-set-name evaluationたとえば次のように実行します。
CUDA_VISIBLE_DEVICES=0 python pretrain.py \
arch=trm \
data_paths="[data/arc1concept-aug-1000]" \
arch.L_layers=2 \
arch.H_cycles=3 arch.L_cycles=4 \
ema=Trueでもかなり時間がかかりますので、はじめは先程やったように軽量にしてテストするのがよいでしょう。
リポジトリの概要 (生成した解説コピペ)
以下では、pretrain.py を中心に、TinyRecursiveModels リポジトリの主要なコードの処理内容をまとめます。
● このコードは一言で言うと何をしているか
- TinyRecursiveModels の各種モデル(TRM や階層型モデルなど)を,パズルデータセット上で事前学習(pretrain)し,ログ出力やチェックポイント保存を行うトレーニングスクリプトです。
● 主要な処理ステップ
- 設定の読み込み
config/cfg_pretrain.yamlからハイパーパラメータやモデルアーキテクチャを読み込む。
- データ準備
puzzle_dataset.pyのPuzzleDatasetでパズル問題データをロードし、DataLoaderを生成。
- モデル・最適化器の初期化
models/recursive_reasoning以下のサブモジュールから指定モデルを構築。- 学習率や重み減衰などを設定し,複数のオプティマイザを用意。
- トレーニングループ
- 各エポック・バッチでフォワード/バックワードを実行し,損失を計算,パラメータ更新。
wandbでメトリクスログを送りつつ,定期的にモデルを保存。
- オプショナルな重みミックス
mix_weights_direct関数で複数モデル間の重みをα比率で合成し,新たなモデルを生成。
● 主要なクラス/関数と役割
| 名前 | 役割 |
|---|---|
PuzzleDataset (puzzle_dataset.py) | パズル問題を読み込み,入力(シーケンス/特徴量)とラベルを返す Dataset |
build_model() (pretrain.py 内) | 設定に応じて TRM/HRM/Transformer ベースラインなどを構築 |
mix_weights_direct() | 複数モデルの state_dict を α 合成し,新モデルに適用 |
train_one_epoch() | 1 エポック分のフォワード・バックワード・更新・ログを実行 |
main() | 全体の処理を統括:設定読み込み→データ準備→モデル初期化→ループ |
● データの入出力フロー
- 入力
- 形式・型:テキスト/数値シーケンス(例:長さ N の整数トークン列)
- 具体例:
[12, 5, 27, 9, …]と正解ラベル3
- 処理
- 埋め込み層でトークンをベクトル化 → 再帰的/階層的モデルに入力 → 最終層で分類/回帰出力
- 損失計算(クロスエントロピーなど)→ 勾配降下
- 出力
- 型:ログ(
wandb)、モデルチェックポイント(.pt) - 具体例:
epoch=10, loss=0.1234のログと,model_epoch10.pt
- 型:ログ(
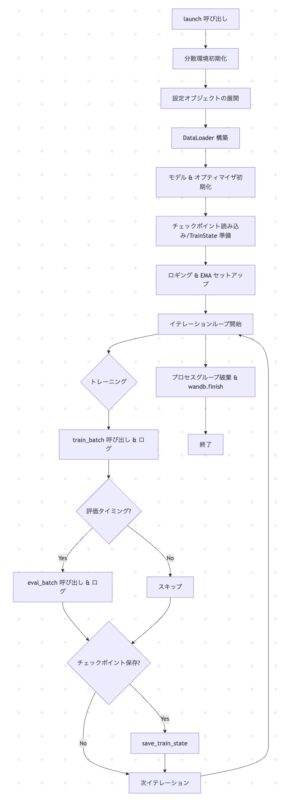
● pretrain.pyのフローチャート
トラブルシュートその2
デフォルトパラメータのままで、 arch=transformers_baselineを実行すると次のエラーがでて止まります。
torch._dynamo.exc.TorchRuntimeError: Dynamo failed to run FX node with fake tensors: call_method view(*(FakeTensor(..., device='cuda:0', size=(768, 82, 12, 42), dtype=torch.bfloat16,
grad_fn=<PermuteBackward0>), 768, 82, 504), **{}): got ValueError('Cannot view a tensor with shape torch.Size([768, 82, 12, 42]) and strides (47232, 48, 3936, 1) as a tensor with shape (768, 82, 504)!')layers.py の Attention.forwardで、Tensorのメモリ配置が不連続なところにview()を使っている事によるよくあるValueエラーです。
次のコードを
attn_output = einops.rearrange(attn_output, 'B H S D -> B S H D')
attn_output = attn_output.view(batch_size, seq_len, self.output_size) # type: ignore次のように.contiguous()を入れるように修正するか
attn_output = einops.rearrange(attn_output, 'B H S D -> B S H D').contiguous()
attn_output = attn_output.view(batch_size, seq_len, self.output_size) # type: ignore次のようにreshape()にして修正します。
attn_output = einops.rearrange(attn_output, 'B H S D -> B S H D')
attn_output = attn_output.reshape(batch_size, seq_len, self.output_size)